오늘 공부할 자료구조는 해시 테이블이다.
해시 테이블은 이번에 처음 접해본 자료구조이다. 은연중에 사용했을지는 모르겠지만 이렇게 개념을 공부하는 건 처음이다. 물론 예전 자바에서 해시 맵(Hash Map)을 사용해보긴 했지만 구체적인 내용은 잘모르기 때문에 한번 공부해 보겠다.
현재 차근차근 해보자는 생각에 기초적인 부분을 공부하고 있다. 좀 더 구체적인 내용은 다른 글에 작성하거나 추후 글을 수정하는 방향으로 해보겠다.
틀린 내용이 있거나 궁금한게 있다면 편하게 댓글 남겨주시면 감사하겠습니다.
📌 개념
해시 테이블(Hash Table)은 해시 함수를 활용해 만든 데이터 구조로, 데이터를 효율적으로 검색할 수 있다.
※ 해시 함수는 추후에 다뤄 볼 예정이다.
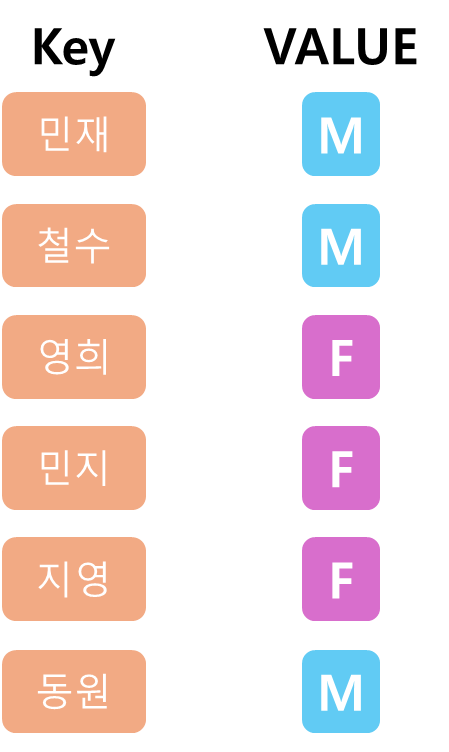
해시 테이블은 키(Key)와 값(Value)을 하나의 짝으로 저장하는 데이터 구조다.
위 예에선 이름을 키로, 성별을 값을 짝으로하여 저장한다.
배열에 담았을 경우
해시 테이블의 특징을 비교해 알아보기 위해, 같은 데이터를 배열에 저장하는 경우도 살펴보겠다.

데이터가 저장된 배열에서 '지영'의 성별을 알고싶다면 지영이 몇 번째 칸에 저장되어 있는지 모르게 때문에 앞에서부터 차례대로 확인해야 한다. 이러한 과정이 선형 탐색이다.
※ 선형 탐색은 나중에 자세히 공부할 예정이다

먼저 왼쪽부터 보면
0번에 저장된 데이터의 키는 민재이다. 지영이 아니기 때문에 다음으로 넘어간다.
다음 1번에 저장된 데이터의 키를 보면 철수이다. 마찬가지로 지영이 아니기 때문에 넘어간다.
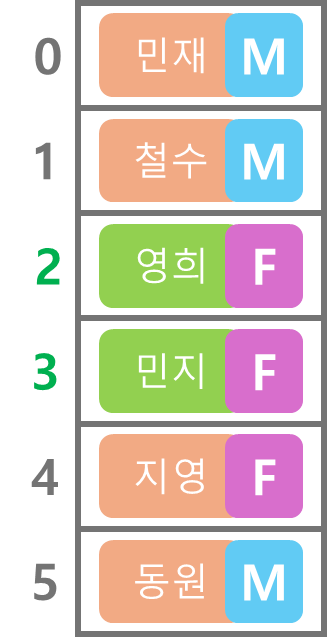
2번과 3번의 경우도 차례대로 살펴보면 데이터의 키가 지영이 아니다.

4번에 담긴 데이터의 키가 지영이고 이에 대응되는 값(성별)은 여성인것을 확인할 수 있다.
이처럼 선형 탐색은 데이터양에 비례하여 계산 시간이 늘어난다. 데이터 탐색 시 시간이 오래 걸리기 때문에 키, 값 데이터를 저장하는 것은 효율적이지 못하다.
해시 테이블의 경우
배열에 담았을 경우와 같은 문제를 해결해 주는 것이 해시 테이블이다.

먼저 데이터를 저장해줄 배열을 준비한다. 5칸의 배열을 준비해 뒀다.

민재 데이터를 먼저 저장하면, 해시 함수를 사용하여 민재의 키(문자열 '민재')에 대한 해시값을 계산한다.
예를 들어 4928이란 해시값으로 나왔다고 가정해보자
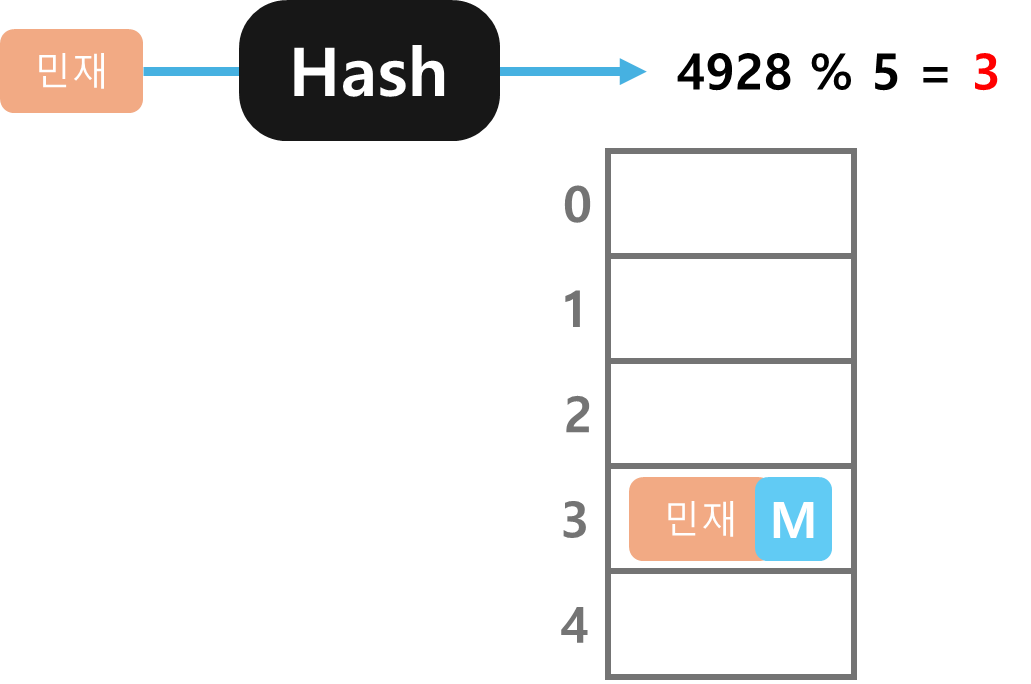
구한 해시값을 배열의 크기인 5로 나눠 나머지를 구한다.
나머지가 3이 나왔기 때문에 3번에 저장을 한다.
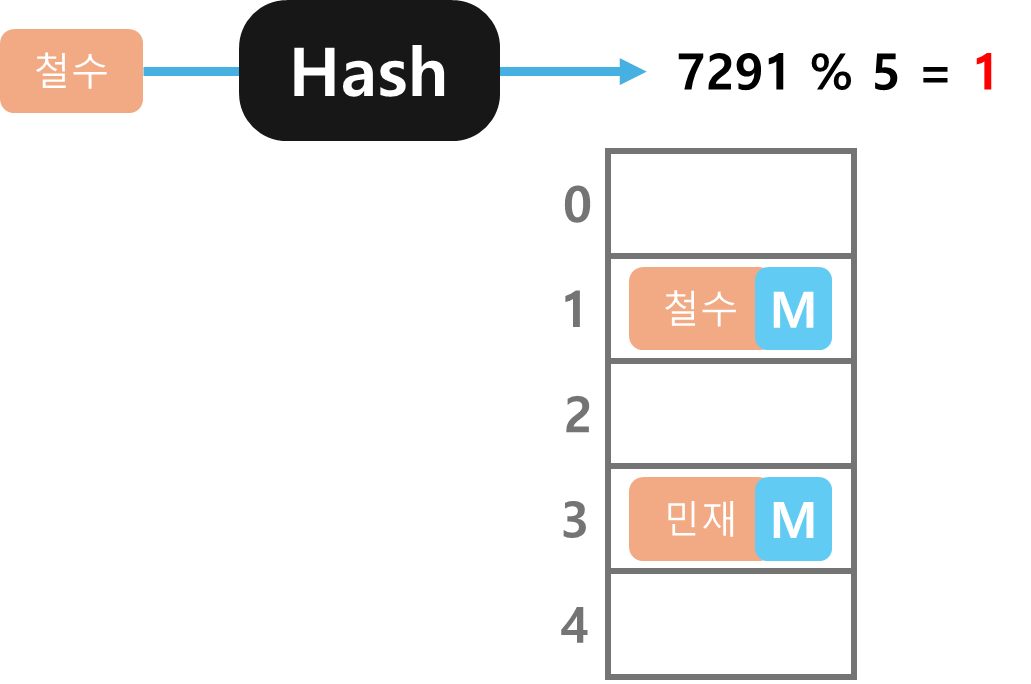
앞에서 구한 동일한 방법으로 철수 데이터의 해시값은 7291이고 이에 나머지를 구하면 1이다.
그래서 배열 1번에 넣어준다.
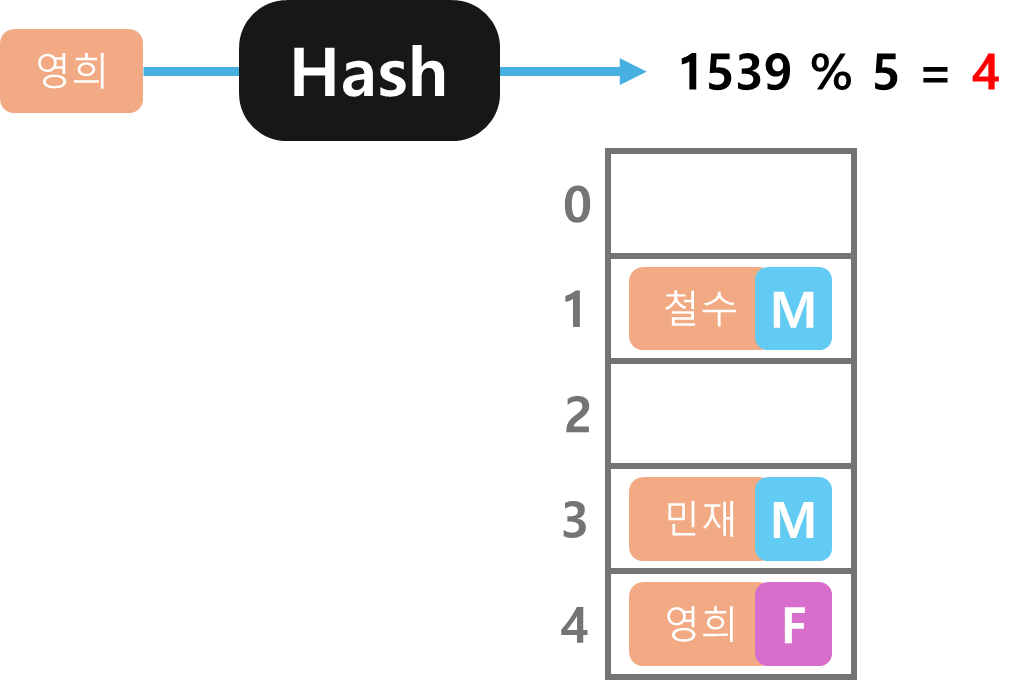
영희 데이터도 마찬가지 과정을 거치면 4번에 저장되었다.

같은 방식으로 민지 데이터도 계산을 해서 나온 1번에 저장하려고 보니 이미 철수 데이터가 들어가 있다. 이렇게 저장 위치가 겹치는 것을 충돌이라고 한다.
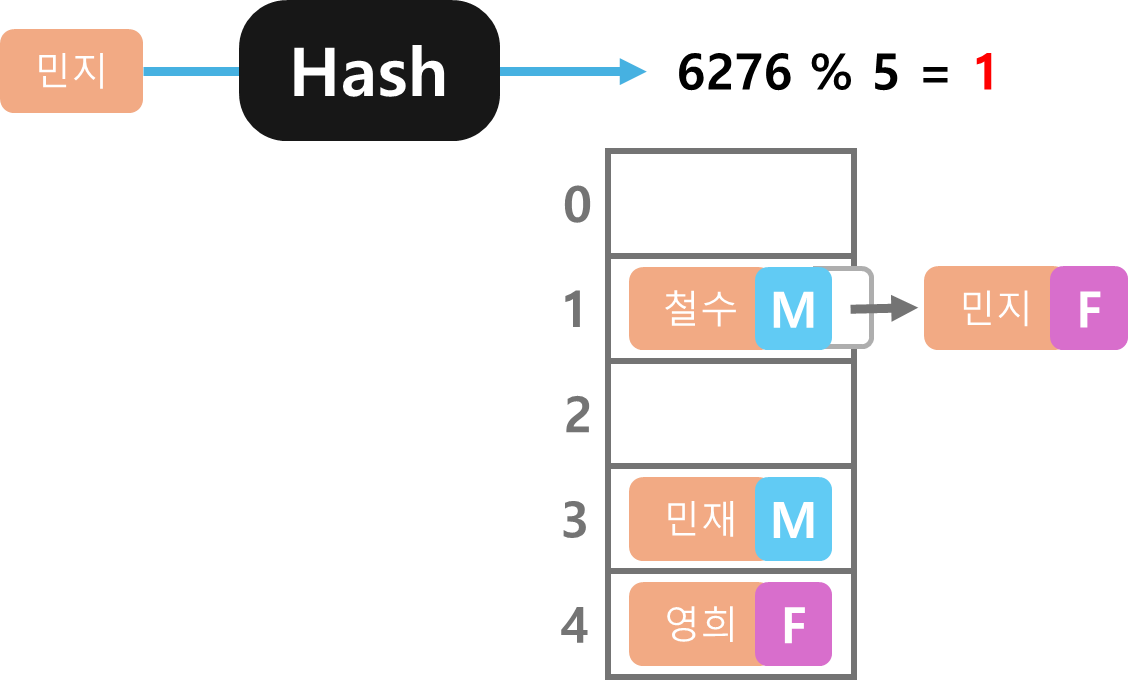
충돌이 일어난 경우 해결하는 방법은 여러가지가 있는데 그 중 하나는 기존데이터와 리스트로 연결하는 것이다.

지영의 데이터의 해시값의 나머지 결과도 3으로 충돌이 있어 리스트로 연결해 준다.
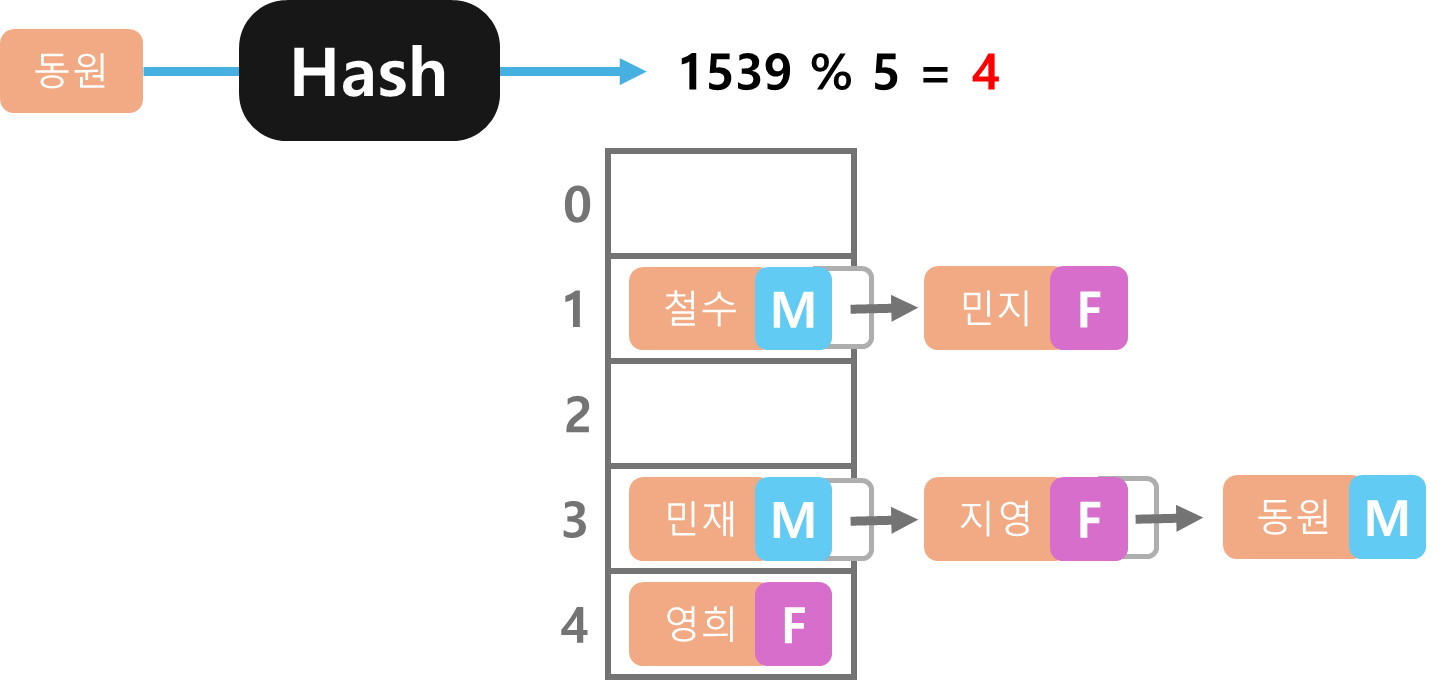
마지막 동원의 데이터의 연산 결과도 4로 충돌이 일어나 지영 다음으로 연결해 준다.
이렇게 모든 데이터가 저장이 완료되었다.
데이터 탐색
이제 데이터를 탐색해 보겠다.
만약 영희의 성별 정보를 알고싶다면

앞서 데이터를 넣을 때 처럼 데이터의 키에 대한 해시값을 5로 나눈 나머지를 구해준다.
그렇게 나온 값이 4이기 때문에 4번 칸에 접근하면 영희 데이터가 나오고 그에 대응하는 값 Female(여성)임을 알 수 있다.
이번엔 리스트의 경우 처럼 지영의 성별을 알아보자
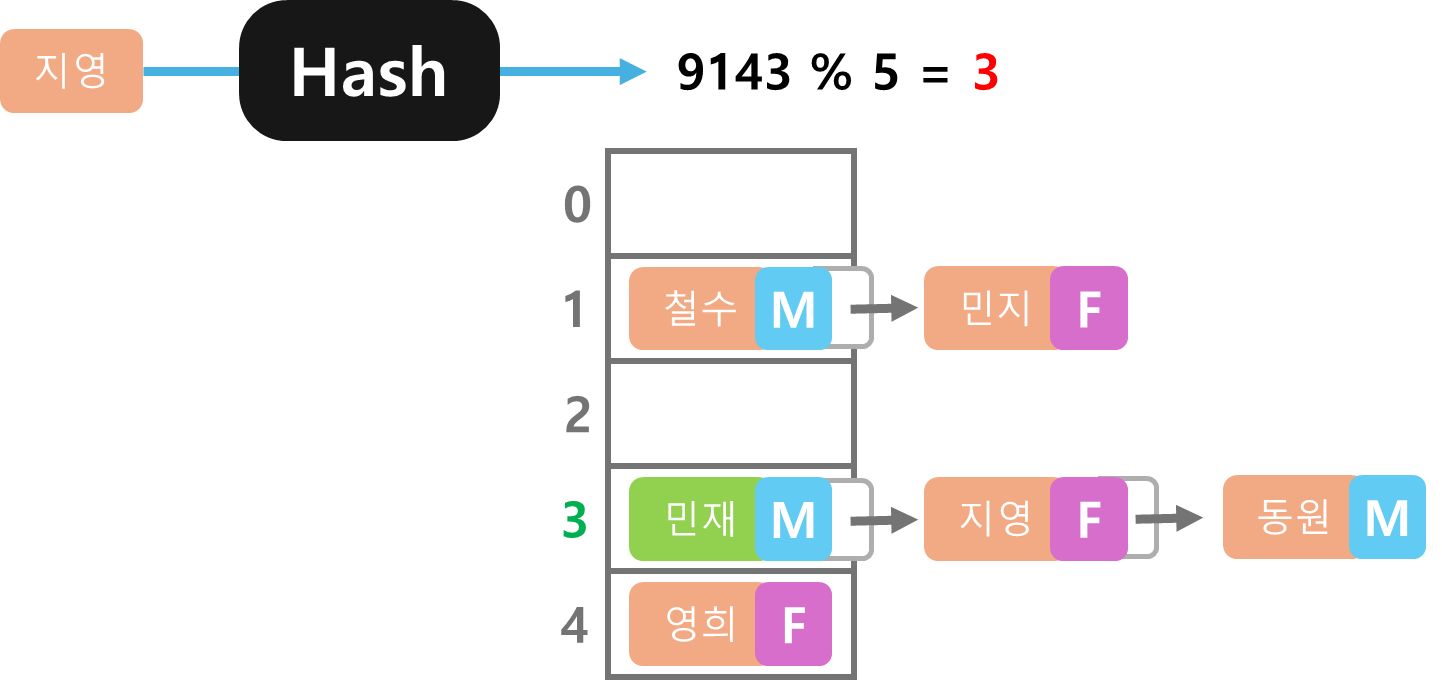
영희 데이터를 탐색한 것 처럼 지영의 키의 해시값을 구해 5로 나눈 나머지에 접근하면 지영이 아닌 민재가 나온다.
여기서 다시 선형 탐색을 시작한다.

선형 탐색을 하면 다음 바로 지영 데이터를 찾을 수 있고 이에 대응하는 성별을 확인하면 여성임을 확인할 수 있다.
이렇게 해시 테이블은 해시 함수를 사용하여 배열 내 데이터에 빠르게 접근할 수 있다.
그리고 위 처럼 충돌 시 리스트를 사용하면 저장할 데이터 수가 정해져 있지 않더라도 유연하게 대응할 수 있다.
하지만 해시 테이블에 사용하는 배열의 크기가 너무 작으면 충돌이 자주 일어나 리스트가 커져 선형 탐색이 많이 발생해 느려진다. 또한 배열의 크기가 너무 크면 비어지게 되는 공간이 많아져 메모리 낭비로 이어진다.
따라서 배열의 크기를 적절하게 설정하는 것이 중요하다.
📌 추가 내용
위에서 데이터를 배열에 저장하다 충돌이 발생하면 리스트를 이용해서 기존 데이터와 연결했다.
이러한 방법을 분리 연결법(separate chaining) 또는 체이닝(chaining)이라고 한다.
이외에도 충돌을 해결하는 방법이 몇가지 있는데, 그중 많이 사용하는 것이 개방 주소법(open addressing)이다.
이 방법은 충돌이 발생하면 다음 공간(배열상 위치)을 찾아 저장한다. 다음 공간도 충돌한다면 그 다음 공간, 또 충돌하면 그다음 공간, 이렇게 충돌하지 않을 때 까지 다음 공간을 찾는다.
이때 다음 공간을 찾는 방법에는 선형 탐사(liner probing), 제곱 탐사법(quadratic probing), 이중 해싱(double hasing probing) 등 이 있다.
선형 탐사(liner probing)는 저장할 위치로 부터 고정된 폭만큼 이동하여 차례대로 검색해 비어있는 곳에 데이터를 저장한다.
제곱 탐사법(quadratic probing)은 해시의 저장순서 폭을 제곱으로 저장하는 방식이다. 예를 들어 충돌이 발생한 경우 1만큼 이동하고, 다음 충돌이 일어나면 2² , 3² 칸씩 옮기는 방식이다.
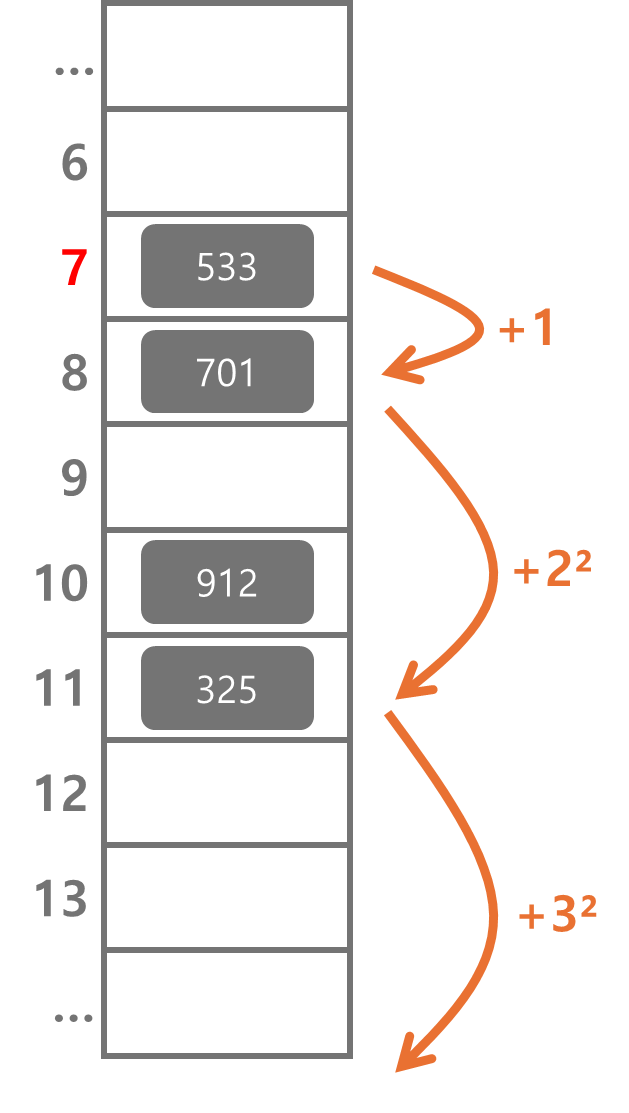
이중 해싱(double hasing probing)은 해시된 값을 한 번 더 해싱하여 해시의 규칙성을 없애버리는 방식이다. 해시된 값을 한 번 더 해싱하여 새로운 주소를 할당하기 때문에 다른 방법들 보다 더 많은 연산을 하게된다.
이러한 개방 주소법은 테이블에 저장된 데이터의 밀도가 높을수록 성능이 급격하게 저하된다는 단점이 있다.
⏱️ 시간복잡도
각 key값을 해시함수에 의한 고유한 인덱스를 가지기 때문에 O(1)의 시간복잡도를 가진다.
하지만 데이터 충돌이 발생한 경우,
체이닝에 연결된 리스트를 검색해야 하기 때문에 O(N)까지 시간복잡도가 증가 할 수 있다.
참고 자료
그림으로 이해하는 알고리즘 : 이시다 모리테루, 미야자키 슈이츠
자료구조 | 해시 테이블 hash table : 요행을 바라지 않는 개발자 https://velog.io/@edie_ko/hashtable-with-js
[자료구조] 해시 테이블(Hash Table) : dam2.log https://velog.io/@do_dam/%EC%9E%90%EB%A3%8C-%EA%B5%AC%EC%A1%B0-%ED%95%B4%EC%8B%9C-%ED%85%8C%EC%9D%B4%EB%B8%94Hash-Table
비선형 데이터구조, 해시(Hash) #5 충돌 해결(Collision Solution) : 김용환 블로그 https://yonghwankim-dev.tistory.com/175
'개발 지식 > 자료구조' 카테고리의 다른 글
| [자료구조] 이진 탐색 트리 (Binary Search Tree) (1) | 2024.07.31 |
|---|---|
| [자료구조] 힙 (Heap) (0) | 2024.07.29 |
| [자료구조] 큐 (Queue) (0) | 2024.07.23 |
| [자료구조] 스택 (Stack) (1) | 2024.07.22 |
| [자료구조] 배열 (Array) (0) | 2024.07.17 |



